
Strictly speaking Bash doesn't support Light-Weight Processes or threads. Nevertheless it is possible to implement a "thread pool"-like script without using any external tools. This can be useful if a high level language (i.e. Java, Python, Perl) is not available and the Bash interpreter is the only tool at hand.
To avoid confusion we'll use the term "pool of workers" instead of "thread pool". The following diagram illustrates the typical use case:
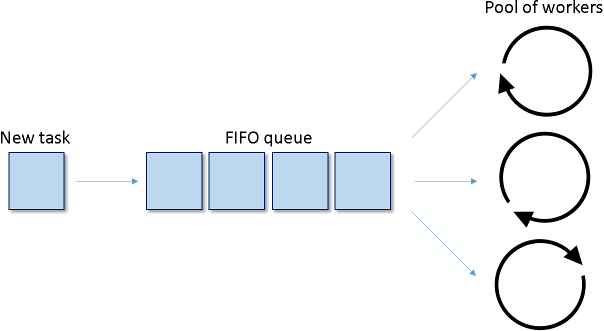
There is a process in charge of producing certain events or records, which can be processed in parallel. Let's call them "tasks". The tasks are inserted into a FIFO queue. There is a pool of workers monitoring the FIFO qoeue. Whenever a worker becomes idle and there is a task pending in the queue the task is dequeued and processed by the spare worker. If all workers are busy the tasks will accumulate in the queue.
Let's split the implementation into 2 components: the worker and the pool.
Worker
The worker contains the code, which will be executed in parallel. This script is not intended to be executed by the user directly. So, let's avoid the file extension ".sh" and the classical "#!/bin/bash" header. The script name can be just worker.
# The first command line argument is a unique ID:
WORKER_ID=$1
# Simple logger
log(){
printf "`date '+%H:%M:%S'` [Worker#%s] %s\n" "$WORKER_ID" "$1" >>worker.log
}
# Wait for the queue
while [ ! -e myqueue ]
do
sleep 1
done
touch mylock
exec 3<myqueue # FD3 <- queue
exec 4<mylock # FD4 <- lock
while true
do
# Read the next task from the queue
flock 4
IFS= read -r -u 3 task
flock -u 4
if [ -z "$task" ]
then
sleep 1
continue
fi
log "Processing task: ${task}"
done
Note that the worker uses a file to synchronize the access to the FIFO queue. The file (mylock) is locked before reading the queue and unlocked after reading the queue. The synchronization is atomic. Therefore, only a single worker can perform a dequeue at a time. This is important to avoid concurrency issues.
In Bash 4 and later it is possible to optimize the logger to avoid starting a subprocess:
log(){
printf '%(%Y-%m-%d %H:%M:%S)T [Worker#%s] %s\n' '-1' "$WORKER_ID" "$1" >>worker.log
}
Pool
The pool is another script, which will start, stop and monitor the pool of workers. This is pool.sh:
#!/bin/bash
# The pool of workers size:
WORKERS=3
# Check the pool status
status(){
alive=0
for p in pid.*
do
[ "$p" = 'pid.*' ] && break
pid="${p:4}"
wk=`ps -fp "$pid" 2>/dev/null | sed -n 's/.* worker //p'`
if [ ! -z "$wk" ]
then
let "alive++"
[ $1 = 0 ] && printf 'Worker %s is running, PID %s\n' "$wk" "$pid"
else
rm -f "$p"
fi
done
if [ $1 = 0 ]
then
[ $alive = 0 ] && printf 'NOK\n' || printf 'OK: %s/%s\n' $alive "$WORKERS"
fi
return $alive
}
# Stop the pool
stop(){
for p in pid.*
do
[ "$p" = 'pid.*' ] && break
pid="${p:4}"
wk=`ps -fp "$pid" 2>/dev/null | sed -n 's/.* worker //p'`
if [ ! -z "$wk" ]
then
kill "$pid" 2>/dev/null
sleep 0
kill -0 "$pid" 2>/dev/null && sleep 1 && kill -9 "$pid" 2>/dev/null
fi
rm -f "$p"
done
}
# Start the pool
run(){
status 1
[ $? != 0 ] && printf 'Already running\n' && exit 0
# Setup the queue
rm -f myqueue mylock
mkfifo myqueue
# Launch N workers in parallel
for i in `seq $WORKERS`
do
/bin/bash worker $i &
touch pid.$!
done
}
case $1 in
"start")
run
;;
"stop")
stop
;;
"status")
status 0
;;
*)
printf 'Unsupported command\n'
;;
esac
Let's start the pool of workers:
test@celersms:~/test$ bash pool.sh start test@celersms:~/test$ bash pool.sh status Worker 1 is running, PID 4454 Worker 2 is running, PID 4457 Worker 3 is running, PID 4460 OK: 3/3
There are 3 workers. As you can see with "ps", each worker is actually a subprocess:
test@celersms:~/test$ ps -fu | grep worker test 4460 0.0 0.1 5292 1288 pts/10 S 22:27 0:00 /bin/bash worker 3 test 4457 0.0 0.1 5292 1288 pts/10 S 22:27 0:00 /bin/bash worker 2 test 4454 0.0 0.1 5292 1288 pts/10 S 22:27 0:00 /bin/bash worker 1
We can stop the pool of workers anytime:
test@celersms:~/test$ bash pool.sh stop test@celersms:~/test$ bash pool.sh status NOK test@celersms:~/test$ ps -fu | grep worker test@celersms:~/test$
In order to increase or decrease the number of workers just modify the value of the WORKERS variable inside pool.sh. Let's start the pool again. After that we can queue a dummy list of tasks by just writing into myqueue:
test@celersms:~/test$ bash pool.sh start test@celersms:~/test$ cat >>myqueue <<EOF > task1 > task2 > task3 > task4 > task5 > task6 > task7 > task8 > task9 > EOF test@celersms:~/test$ cat worker.log 22:40:26 [Worker#3] Processing task: task1 22:40:26 [Worker#2] Processing task: task2 22:40:26 [Worker#1] Processing task: task3 22:40:26 [Worker#3] Processing task: task4 22:40:26 [Worker#1] Processing task: task5 22:40:26 [Worker#2] Processing task: task6 22:40:26 [Worker#3] Processing task: task7 22:40:26 [Worker#1] Processing task: task8 22:40:26 [Worker#2] Processing task: task9
The dummy tasks were processed asynchronously. Each worker was executed in a random order, but the overall workload was distributed evenly.
Sample project
 A complete sample project
containing the Bash scripts is available in our GitHub repository.
The code was tested in Bash V3.2.25 and later.
A complete sample project
containing the Bash scripts is available in our GitHub repository.
The code was tested in Bash V3.2.25 and later.

