
Estríctamente hablando, Bash no soporta procesos ligeros o hilos. Sin embargo, es posible implementar un script funcionalmente muy similar a un "pool de hilos" sin usar herramientas externas. Esto puede ser útil si no es posible usar lenguajes de alto nivel como Java, Python, Perl, etc. En algunos casos el intérprete de Bash es la única herramienta disponible.
Para evitar confusión usaremos el término "pool de trabajo" en lugar de "pool de hilos". El siguiente diagrama ilustra el caso de uso típico:
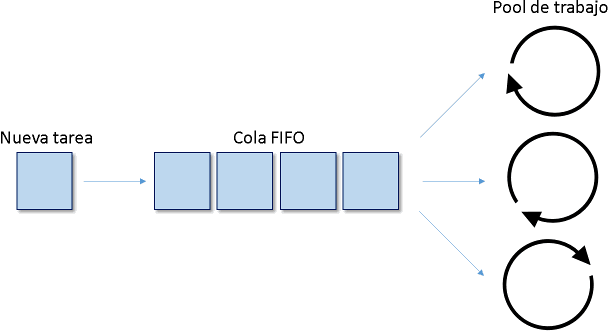
Existe un proceso encargado de generar ciertos eventos o registros, los cuales pueden ser procesados en paralelo. Podemos llamarlos "tareas". Las tareas ingresan en una cola FIFO. Existe un pool de trabajo vinculado con la cola FIFO. Cuando uno de los trabajadores (o workers) se encuentra libre y existe al menos una tarea pendiente en la cola, esta tarea es desencolada y procesada por dicho worker. Si todos los worker se encuentran ocupados las tareas se acumularan en la cola.
Separaremos la implementación en 2 componentes: el worker y el pool.
Worker
El worker contiene el código, el cual se ejecutará en paralelo. Este script no debe ser ejecutado diréctamente por el usuario. Por lo tanto, se recomienda evitar el uso de la extensión ".sh" y el encabezado "#!/bin/bash" dentro del script. El nombre del script podría ser símplemente worker.
# El primer argumento de linea de comandos es un ID unico:
WORKER_ID=$1
# Un logger basico
log(){
printf "`date '+%H:%M:%S'` [Worker#%s] %s\n" "$WORKER_ID" "$1" >>worker.log
}
# Esperamos hasta que la cola este disponible
while [ ! -e myqueue ]
do
sleep 1
done
touch mylock
exec 3<myqueue # FD3 <- cola
exec 4<mylock # FD4 <- lock
while true
do
# Leemos la siguiente tarea desde la cola
flock 4
IFS= read -r -u 3 task
flock -u 4
if [ -z "$task" ]
then
sleep 1
continue
fi
log "Procesando tarea: ${task}"
done
Nótese que el worker utiliza un fichero para sincronizar el acceso a la cola FIFO. Este fichero (mylock) es bloqueado antes de leer la cola y liberado después de la lectura. Esta sincronización es atómica. Por lo tanto, sólamente uno de los worker puede desencolar una tarea a la vez. Esto es importante para evitar errores de concurrencia.
En Bash 4 y posterior es posible optimizar la función de log para evitar crear un subproceso:
log(){
printf '%(%Y-%m-%d %H:%M:%S)T [Worker#%s] %s\n' '-1' "$WORKER_ID" "$1" >>worker.log
}
Pool
El pool es otro script, el cual se encarga de iniciar, detener y monitorear el pool de trabajo. Este es pool.sh:
#!/bin/bash
# El numero de workers en el pool:
WORKERS=3
# Verificar estado del pool
status(){
alive=0
for p in pid.*
do
[ "$p" = 'pid.*' ] && break
pid="${p:4}"
wk=`ps -fp "$pid" 2>/dev/null | sed -n 's/.* worker //p'`
if [ ! -z "$wk" ]
then
let "alive++"
[ $1 = 0 ] && printf 'Worker %s activo, PID %s\n' "$wk" "$pid"
else
rm -f "$p"
fi
done
if [ $1 = 0 ]
then
[ $alive = 0 ] && printf 'NOK\n' || printf 'OK: %s/%s\n' $alive "$WORKERS"
fi
return $alive
}
# Detener el pool
stop(){
for p in pid.*
do
[ "$p" = 'pid.*' ] && break
pid="${p:4}"
wk=`ps -fp "$pid" 2>/dev/null | sed -n 's/.* worker //p'`
if [ ! -z "$wk" ]
then
kill "$pid" 2>/dev/null
sleep 0
kill -0 "$pid" 2>/dev/null && sleep 1 && kill -9 "$pid" 2>/dev/null
fi
rm -f "$p"
done
}
# Iniciar el pool
run(){
status 1
[ $? != 0 ] && printf 'Ya se ha iniciado\n' && exit 0
# Configurar la cola
rm -f myqueue mylock
mkfifo myqueue
# Lanzar N workers en paralelo
for i in `seq $WORKERS`
do
/bin/bash worker $i &
touch pid.$!
done
}
case $1 in
"start")
run
;;
"stop")
stop
;;
"status")
status 0
;;
*)
printf 'Comando no soportado\n'
;;
esac
Iniciemos el pool de trabajo:
test@celersms:~/test$ bash pool.sh start test@celersms:~/test$ bash pool.sh status Worker 1 activo, PID 4454 Worker 2 activo, PID 4457 Worker 3 activo, PID 4460 OK: 3/3
Se han iniciado 3 worker. Como puede ver con "ps", cada worker es en realidad un subproceso:
test@celersms:~/test$ ps -fu | grep worker test 4460 0.0 0.1 5292 1288 pts/10 S 22:27 0:00 /bin/bash worker 3 test 4457 0.0 0.1 5292 1288 pts/10 S 22:27 0:00 /bin/bash worker 2 test 4454 0.0 0.1 5292 1288 pts/10 S 22:27 0:00 /bin/bash worker 1
En cualquier momento podemos detener el pool de trabajo:
test@celersms:~/test$ bash pool.sh stop test@celersms:~/test$ bash pool.sh status NOK test@celersms:~/test$ ps -fu | grep worker test@celersms:~/test$
Para aumentar o disminuir el número de workers en el pool sólamente se debe modificar el valor de la variable WORKERS dentro de pool.sh. Iniciemos nuevamente el pool de trabajo. Luego de eso podemos encolar una serie de tareas de prueba, para lo cual simplemente se debe escribir en myqueue:
test@celersms:~/test$ bash pool.sh start test@celersms:~/test$ cat >>myqueue <<EOF > tarea1 > tarea2 > tarea3 > tarea4 > tarea5 > tarea6 > tarea7 > tarea8 > tarea9 > EOF test@celersms:~/test$ cat worker.log 22:40:26 [Worker#3] Procesando tarea: tarea1 22:40:26 [Worker#2] Procesando tarea: tarea2 22:40:26 [Worker#1] Procesando tarea: tarea3 22:40:26 [Worker#3] Procesando tarea: tarea4 22:40:26 [Worker#1] Procesando tarea: tarea5 22:40:26 [Worker#2] Procesando tarea: tarea6 22:40:26 [Worker#3] Procesando tarea: tarea7 22:40:26 [Worker#1] Procesando tarea: tarea8 22:40:26 [Worker#2] Procesando tarea: tarea9
Las tareas de prueba fueron procesadas de manera asíncrona. Cada uno de los worker fue ejecutado en orden aleatorio, pero la carga de trabajo fue distribuida de manera equitativa.
Ejemplo de proyecto
 Un ejemplo de proyecto completo,
incluyendo los scripts de Bash, está disponible en nuestro repositorio de GitHub.
El código fue probado en Bash V3.2.25 y posteriores.
Un ejemplo de proyecto completo,
incluyendo los scripts de Bash, está disponible en nuestro repositorio de GitHub.
El código fue probado en Bash V3.2.25 y posteriores.

